 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 用Presto-Amazon Kinesis连接器实现流数据交互式查询
发布日期:2016-4-24 15:4:40
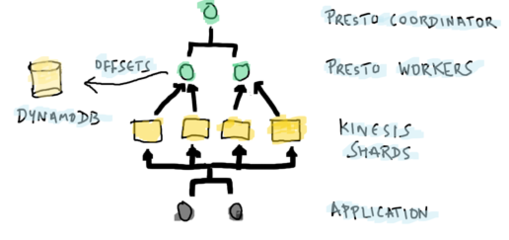
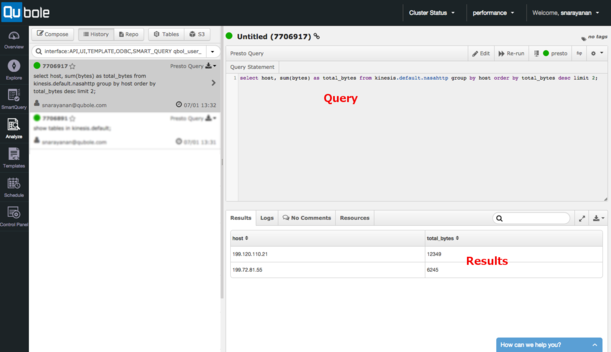
用Presto-Amazon Kinesis连接器实现流数据交互式查询 Amazon Kinesis是一项可伸缩的,完全托管业务,可以流化大规模的分布式数据集。随着各种应用开始收集越来越多的数据,Amazon Kinesis正在成为将数据摄入AWS的起始点。但所有那些数据只有在其可以被分析并用来影响商业决策时才是有用的。很多解决方案由于以各种方式处理数据而可以消耗Kinesis流,但是没有一种解决方案能够使用SQL提供近乎实时的Kinesis查询。在Qubole的我们也意识到了这一点,并从事于针对Kinesis的Presto连接器的研究。 Presto旨在满足交互式,近乎实时的SQL查询场景。最初是由Facebook开发并开放其资源代码,从那时起Presto已经广泛地被诸如Netflix,Dropbox和Airbnb这样的组织采用去交互性地查询千万亿字节规模的数据集。在Qubole,我们在AWS上提供 Presto as a Service(Presto即服务),所以我们的终端客户,典型的客户是数据科学家与商业分析师,可以轻松地开始交互式SQL查询。Qubole管理底层的Presto集群配置,自动提供与伸缩集群规模来满足任务要求。 在亚马逊S3中存储数据,我们的大部分客户使用Presto,Hive,mysql,Spark与MapReduce(Qubole将所有这些以服务的形式提供)共同完成交互式的批量工作负载。但是随着Presto实现了快速的交互式处理,越来越多的客户那有实时流数据源(例如Amazon Kinesis)查询的需求。我们为了满足这一需求,为Presto构建了 open source connector(开放源连接器),从Kinesis直接读取与查询数据。下面的图为我们展示了连接器的工作原理(该草图是受Martin Kleppman的博客启发)。如图1所示: 用户应用将数据推入Kinesis碎片。Presto集群包括很多处理进程与一个协调器进程。Kinesis连接器将每一个碎片映射到一个处理进程,每个处理进程使用 GetRecordsAPI从碎片中读取数据。Kinesis中的每条记录只是一个二进制对象,连接器必须被告知如何将其作为一张逻辑表进行翻译。作为表定义(后面会讲到)的一部分,用户告诉连接器如何翻译这个对象。然后连接器将Kinesis记录翻译成表记录,然后表记录会在Presto引擎中经过不同的查询阶段被处理。每一个处理进程也会视需要在DynamoDB表中记录它们在每一个碎片中已读取了多少数据。这在本篇文章稍后描述的检查点特性中也被用到。 用一个示例应用来展示在Qubole范围内该连接器的能力。该应用将会把我们带回到90年代,当时NASA( 美国国家航空和宇宙航行局)向位于佛罗里达的NASA肯尼迪航天中心的万维网服务器发出公开的HTTP请求。为了能返回到那个年代,遵循下面所示的的步骤。 第一步:你需要一个AWS账户来访问Kinesis数据流。这样确保你创建数据的这台电脑可以通过DefaultAWSCredentialsProviderChain叙述的设置访问Kinesis。比如,你可以设置环境变量AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY。 第二步:下载,构建,解压缩 kinesis-data-gen工具。使用这个工具创建名为nasahttp的Amazon Kinesis数据流,并将JSON形式的http日志推入数据流中。你可以使用sample_data.txt作为种子数据。如下面所示: localhost datagen-0.0.1-SNAPSHOT]$ ./bin/kinesis-datagen -f etc/sample_data.txt -create -n nasahttp -s 1 Jun 29, 11:01:26 AM com.qubole.kinesis.nasa.DataGenerator safeDeleteStream INFO: trying to delete nasahttp Jun 29, 11:01:32 AM com.qubole.kinesis.nasa.DataGenerator safeDeleteStream INFO: stream nasahttp not found Jun 29, 11:01:36 AM com.qubole.kinesis.nasa.DataGenerator safeCheckStream INFO: waiting for stream to become active Jun 29, 11:01:36 AM com.qubole.kinesis.nasa.DataGenerator safeCheckStream INFO: CREATING Jun 29, 11:01:38 AM com.qubole.kinesis.nasa.DataGenerator safeCheckStream INFO: CREATING Jun 29, 11:02:25 AM com.qubole.kinesis.nasa.DataGenerator safeCheckStream INFO: ACTIVE Jun 29, 11:02:25 AM com.qubole.kinesis.nasa.DataGenerator pushRecords INFO: opening file etc/sample_data.txt Jun 29, 11:02:25 AM com.qubole.kinesis.text.FileLineReader end INFO: records = 9 Jun 29, 11:02:25 AM com.qubole.kinesis.executor.StreamProducerRunnable run INFO: producer is done Jun 29, 11:02:25 AM com.qubole.kinesis.executor.StreamExperiment runExperiment INFO: producer is done Jun 29, 11:02:25 AM com.qubole.kinesis.executor.StreamExperiment runExperiment INFO: waiting for consumers to finish Jun 29, 11:02:25 AM com.qubole.kinesis.nasa.RecordParser parseRecord SEVERE: unable to parse: Jun 29, 11:02:26 AM com.qubole.kinesis.executor.StreamConsumerRunnable run INFO: no-op count 1 Jun 29, 11:02:26 AM com.qubole.kinesis.executor.StreamExperiment runExperiment INFO: Produced 9 records Jun 29, 11:02:26 AM com.qubole.kinesis.executor.StreamExperiment runExperiment INFO: Consumed 9 records Jun 29, 11:02:26 AM com.qubole.kinesis.executor.StreamExperiment runExperiment INFO: Total time 1.16748948 seconds Jun 29, 11:02:26 AM com.qubole.kinesis.executor.StreamExperiment runExperiment INFO: Records per second 7.7088489054308225 第三步:要创建一个更大的数据流,从这里下载NASA HTTP请求。你可以使用这些文件作为示例文件来填充数据发生器。 第四步:在Qubole中注册一个账户,使用Qubole的Presto即服务。你可以输入你的AWS证书,访问你创建的Amazon Kinesis数据流。这篇简短的指南将会指导你如何设置你的Presto集群。 第五步:一旦你在Qubole创建了账户,你就会在你的Clusters页面看到自动配置的Presto集群。点击编辑图标,查看集群配置详情并滚动到Presto Settings部分。如图2所示: 第六步:你可以在这一部分输入以下文本。你可以阅读维基百科页的 Connector Configuration和 Table Definitions部分来详细地理解该文本的含义。如下面所示: config.properties: datasources=jmx,hive,kinesis catalog/kinesis.properties: connector.name=kinesis kinesis.table-names=nasahttp kinesis/nasahttp.json: { "tableName": "nasahttp", "schemaName": "default", "streamName": "nasahttp", "message": { "dataFormat": "json", "fields": [ {"name": "host", "mapping": "host", "type": "VARCHAR"}, {"name": "at", "mapping": "timestamp", "type": "VARCHAR"}, {"name": "request", "mapping": "request", "type": "VARCHAR"}, {"name": "code", "mapping": "code", "type": "BIGINT"}, {"name": "bytes", "mapping": "bytes", "type": "BIGINT"} ]} } 第七步:返回到Analyze页面,构建针对该表的Presto命令。下面的截图展示了Analyze页面的各个组成部分。第一个Presto查询将会启动集群,启动过程可能持续大约2分钟。在查询进行过程中你将会看到包含进程信息的日志,查询完成后,你将会看到查询结果。该示例中的查询结果列出了向HTTP服务器请求最多字节的主机。如下所示: select host, sum(bytes) as total_bytes from kinesis.default.nasahttp group by host order by total_bytes desc limit 2; 如图3所示: 刚刚你已使用Presto对Amazon Kinesis数据流进行了你的第一次SQL查询。你可以使用相同的kinesis-datagen工具(不要使用-create选项)将附加的数据插入到Kinesis中,重新进行同样的查询。你将会在total_bytes列看到不同的数字。 Presto-Amazon Kinesis连接器也支持检查点查询。若你想查询自上次查询以来的增量数据,你可以使用该特性。例如,你可以使用该特性创建一个仪表板来显示每分钟内的前五名请求者。你可以 参阅检查点文档来查看如何使用该特性。 该连接器是开源的(使用Apache许可证),可从 github上获得。 README文件向你描述了如何创建针对特定Presto版本的连接器和如何安装二进制文件。 配置维基百科页将会向你展示正确的配置元素,使你能够连接到Amazon Kinesis。 表定义维基百科页则向你展示了如何描述Presto-Amazon Kinesis表,包括数据格式和字段映射。你也可以发现关于如何在你的笔记本电脑或集群中安装和运行Presto的说明。 最后,Amazon Kinesis只能将数据保存特定的期限。每天将数据以更适于分析的格式,如ORC或Parquet,mysql,卸载到S3中,是很令人满意的。Hive很适合这个使用案例。我们已经构建了Amazon Kinesis存储处理器(可从 github上获取),并开放其资源代码。该存储处理器可在Hive中使用,从Amazon Kinesis中直接查询,并以优化的格式,像ORC或者Parquet,将查询结果写入到HDFS或S3中的分段表中。该连接器也支持设置检查点的Amazon Kinesis访问,确保数据一旦做过历史分析就会被准确地写出。 原文链接:http://blogs.aws.amazon.com/bigdata/post/Tx2DDFNHXSAAH2G/Presto-Amazon-Kinesis-Connector-for-Interactively-Querying-Streaming-Data
上一条: phpMyAdmin无需填写IP管理实现多个MySQL实践 下一条: 数据库深度解析 --NoSQL
|




 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved