 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 你好!PostgreSQL
发布日期:2016-4-21 11:4:37
你好!PostgreSQL 差不多于5年前Olery成立。始于Ruby代理开发的单一产品(Olery Reputation),随着时间的推移,我们开始致力于一系列不同的产品与应用程序。现在,我们的产品有:
在不久的将来,它可以嵌入到网站和更多产品/服务中,我们将会有更多的产品。 我们增加了很多应用程序的数量。现在,我们已经部署了超过25个不同的应用程序(全为Ruby),它们中的一些为web应用程序(Rails或Sinatra),但是大多数的是后台运行程序。 迄今为止我们所取得的成就,是我们最引以为豪的。不过在这些成就的背后总存在着一样东西--基础数据库。我们从Olery成立之日起就安装了数据库:
一开始,这样的安装运行的非常好,然而,随着公司的成长,我们开始遇到了各种各样的问题,尤其是MongoDB的问题居多,mysql的问题少一些。其中一些问题是由于应用与数据库的交互方式而引起的,一些则是由数据库本身而产生的。 比如,我们需要某个时刻从MongoDB中删除一百万个文档,以后再把这些数据重新插入到MongoDB里。这样的处理方法使得整个数据库几乎要被锁定数个小时,浪费时间,自然服务性能就会降低,直到对数据库执行修复(即在MongoDB上执行repairDatabase命令)后才会解锁,完成修复还要花费数个小时,修复所花的小时数要根据数据库的大小来确定。这无疑是效率不高的。 我们在另一实例中注意到我们的应用程序的性能降低与设法跟踪到的 MongoDB 集群。然而,通过进一步检查,我们无法找到问题的真正原因。无论我们怎么安装,或者使用什么工具敲了什么命令我们都找不到原因。直到我们更换了集群的初选,性能才恢复正常。 然而这只是两个例子,我们已经遇到过许多这样的情况。这个问题的核心是,这不只数据库在运行,而且无论我们何时察看它都没有绝对的迹象表明是什么原因导致的问题。 一、无模式的问题 另外,我们面对的核心问题是mongoDB的重要特征之一:模式的缺乏。虽然模式的缺乏可能听起来是有趣,而且在一些情况下是有好处的。但是,对于许多无模式存储引擎的用法,其导致了一些模式之间的内部问题。这些模式没有通过你的存储引擎定义而是通过你的应用的行为及其可能的需要而定义的。 比如:你可能有一页存储你的应用需要的字符串类型的title字段的集合。这儿这个模式是非常符合当前情形的,即使它没有被明确的定义。但是如果这个数据结果改变超时,尤其是如果原来的数据没有被迁移到新的数据结构,这就成了问题(在一些无模式的存储引擎上是相当有问题的)。例如,你可能有Ruby代码,如图1所示的代码:
图1 这样,通过针对每一个有“title”字段并返回一个String的文档,它都能正常工作。然而,对于那些使用不同字段名字(例如:post_title)或根本没有标题字段的文档来说,它则会不能正常工作。为了处理这种情况,就需要我们将代码调整,调整内容如tu 2所示:
图2 另一种处理方法是,在你的模型中定义一个模式。比如 Mongoid,一个流行的针对Ruby的MongoDB ODM,就能让你做到这一点。然而,当使用这些工具定义一个模式时,你可能会好奇为什么它们不在数据库内定义该模式。实际上,这样做可以解决另一个问题:可重用性。如果你只有一个应用程序,那么在代码中定义模式并不是什么大问题。可是,如果你有许多应用程序的话,这将很快会成为一个大麻烦。 无模式存储引擎希望通过删除对模式的限制的方式,让你的工作变得更简单。但现实的情况是,确保数据一致性的责任推到了用户自己的身上。有时候无模式引擎可以工作,但我打赌,更多的时候是事与愿违。 二、好数据库的需求 Olery有了更多的特殊需求后,迫使我寻求一款更好的数据库来解决问题。对于系统,特别是数据库,我们非常注重以下四点:
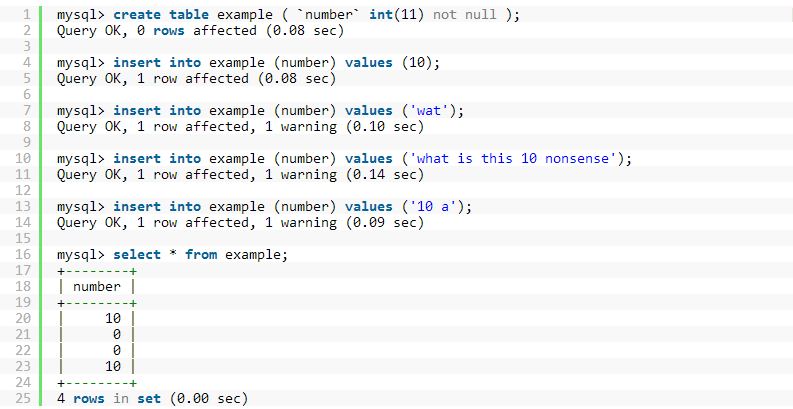
三、搬离MongoDB 将上面的需求牢记于心后,我们就开始寻找一个可以取代MongoDB的数据库。上面提到的特性通常是传统RDBM特征的一组核心集,因此我们锁定了两个候选者:MySQL或者PostgreSQL。 本来MySQL是我们的第一候选,原因是我们的一些关键数据已经在使用它存储。但是,MySQL也有一些问题。比如,当将一个字段定义为int(11)时,你却可以轻松地向该字段插入文本数据,由于MySQL会试图对它进行转换。下面我们举一些例子,代码如图3所示:
图3 值得我们注意的是,MySQL在这些情况下会发出警告。但是,仅仅是警告而已,它们通常(若非总是)会被忽略。 此外,MySQL还有一个问题,任何表的修改操作(例如:添加一列)都会导致表被锁,此时将无法进行读或写操作。这就意味着,使用这种表的任何操作都不得不等待修改完成之后才能进行。对于包含有大量数据的表,这可能会花费几个小时才能完成,很可能会导致应用程序宕机。这个问题已经导致一些公司(例如SoundCloud)不得不自己开发工具(例如lhm)来解决该问题。 了解到上面的问题后,我们开始调查PostgreSQL。PostgreSQL可以解决很多MySQL不能解决的问题。比如,PostgreSQL中你不能将文本数据插入一个数字字段,如图4所示的代码段: 图4 PostgreSQL 还具有在许多方式中不需要每一个操作都上锁就可以改写表的能力。比如,添加一列没有默认值却可以设置为null的列并能够快速完成无需锁定整个表。 还有其他各种有趣的功能,如在 PostgreSQL 可以:
还可以实现更多。 最重要的是PostgreSQL在性能,可靠性,正确性与一致性之间能够权衡。 四、迁移到PostgreSQL 为了在所关心的各种项目之中达到平衡,我们决定使用PostgreSQL。将整个平台从MongoDB迁移到一个截然不同的数据库,这并不是很容易的事,所以为了使转移工作简单化,我们将此过程分成了一下3个步骤:
第一步:部分数据迁移 在考虑把所有数据迁移到新数据库之前,我们先迁移了一小部分数据来做测试。仅仅是迁移一小部分数据就有非常多的麻烦的话,那么我们将数据库迁移也就没什么意义了。 尽管有现成的工具可以利用,但还是有些数据(比如,列重命名,数据类型不一致)要做转换,对于这些数据我们自己开发了些工具。这些工具中,大部分都是Ruby写的一次性脚步,用于删除一些评论,整理数据编码,修正主键发生序列等等。 在测试开始阶段尽管有些数据上的问题,并没有出现大的会阻碍迁移的问题。例如,有些用户提交的数据没有完全按格式编码,导致这些数据被重新编码之前,不能被导入到新数据库。例外一个有意思的改变是,之前评论的数据存的是评论用的语言的名称(如“荷兰语”,“英语”等),现在改了存语言的编码,由于我们新的语义分析系统使用的是语言编码,而不再是语言名称。 第二步:更新应用 目前为止,花费时间最多的就是更新应用,尤其是那些严重依赖MongoDB聚合框架的应用。扔掉那少数几个遗留的Rails应用吧,光是测试就会花掉你几个星期的时间。更新应用的过程大致有以下几个过程:
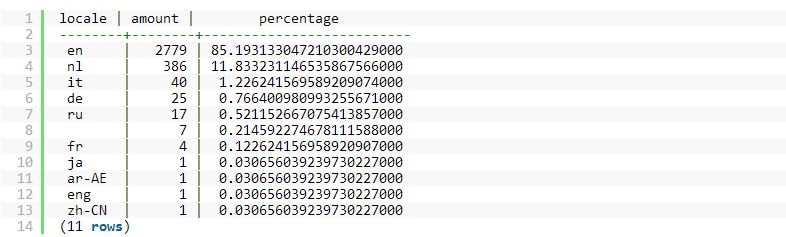
对于非Rails应用,我们推荐使用 Sequel,对于Rails应用,我们现在还无法摆脱ActiveRecord(至少是现在)。Sequel是一个非常好的数据库工具集,它支持绝大多数(如果不是全部)我们想使用的PostgreSQL特性。相较于ActiveRecord,它基于DSL的query要强大的多,尽管可能耗时会有点长。 举个例子,假设你想计算有多少用户使用某种语言,并计算每种语言所占的比例(相对于整个集合)。纯粹的SQL查询语句,如下面的图5所示:
图5 在我们的例子中,将会产生以下输出(当使用PostgreSQL命令行界面时),输出结果如下面的图6所示:
图6 Sequel允许你使用纯Ruby编写上面的查询,而不需要字符串分段(ActiveRecord经常需要),代码如下面的图7所示:
图7 如果你不喜欢使用“Sequel.lit(“*”)”,你也可以使用如图8所示的语法:
图8 虽然这可能有些冗长,但是上面的两种查询都使得它们更易于重用,而无需进行字符串连接。 未来可能也会将我们的Rails应用程序迁移到Sequel,但是考虑到Rails与ActiveRecord耦合得如此紧密,所以我们还不完全确定这是否值得花费时间和精力。
第三步:迁移生产数据 最终我们来到迁移生产数据的过程。一般有两种方法来做这件事:
第一个选项具有一个明显的缺点:停机时间。第二个选项不需要停机但是很难处理。例如,在这个方案中,当你迁移数据的同时,你必须要考虑所有将要添加的数据,否则你就会损失数据。 幸运的是,Olery有一个独特的方案就是我们的数据库的绝大多数写操作都是相当定期的,经常变化的数据(例如用户通讯录信息)只占总数据量的一小部分,相比起我们检查数据,迁移它们花费的时间相当的小。 这部分的基本流程是:
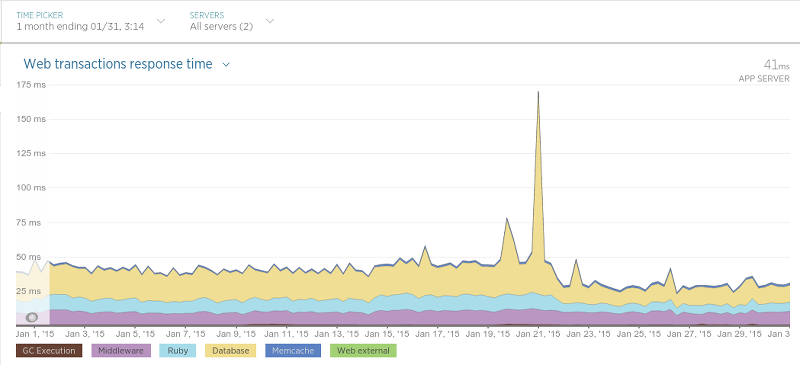
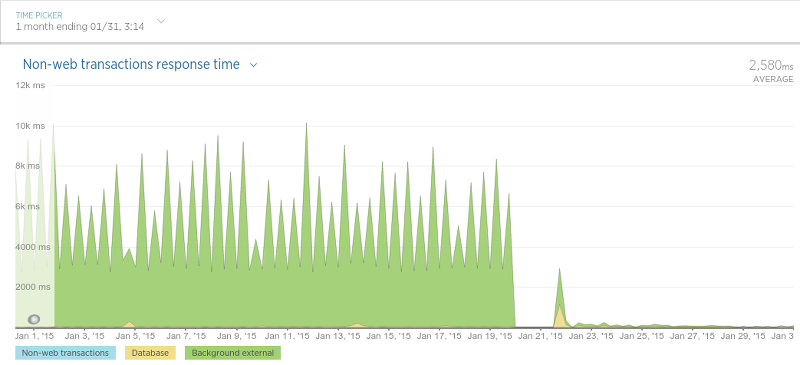
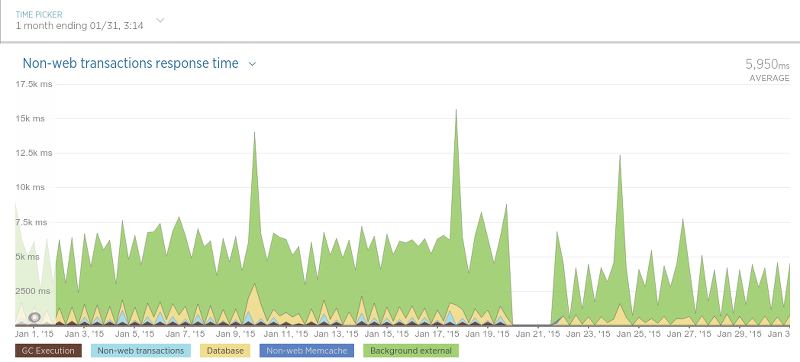
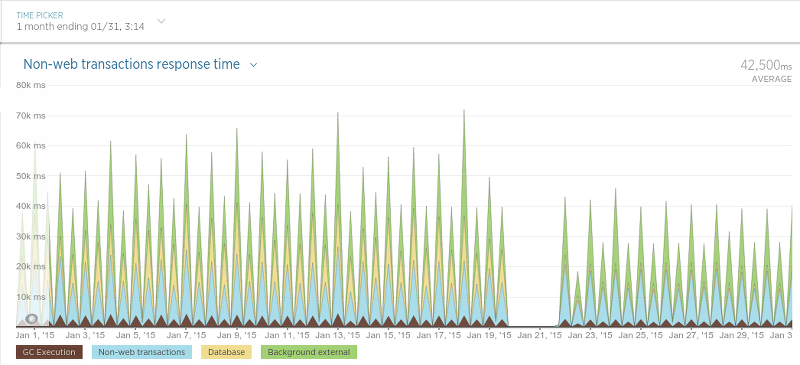
到目前为止,第二步花费的时间最长,大约为24小时。另一方面,迁移步骤1和5中提到的数据只花了45分钟。 五、结论 我们迁移完成并且直到非常满意大概过去了一个月。到现在为止除了那些积极的影响,还曾在各种情况中让应用的性能大幅提高。举例来说,我们的 酒店评论数据API(Hotel Review Data API)(在Sinatra运行)相比迁移之前交互延迟变低了许多,如图9所示: 迁移是在1月21日开始的,高峰表示应用性能的硬重启(在处理期间导致交互时间轻微变慢)。在21日之后交互的平均时间大致是原来的一半。 在另外一种被我们称作“评论持久化”(译者注:即存储评论)的过程中,我们发现了性能上巨大的提升。后台程序目标很简单:保存评论数据(评论内容,评论分数等等)。当我们最终完成了为迁移工作做的很多大的更改后,结果令人振奋,如图10所示: 抓取器也变的更快了,如图11所示: 抓取器性能提升没有评论存储的过程那样大,因为抓取器只用数据库来查询某个评论是否存在(一个相对很快的操作),所以这样的结果并不很令人吃惊。 最后来到程序里用来调度抓取过程的进程(简单称之为“调度器”),如图12所示: 由于调度器只是以固定频度运行,这个图可能有点难以理解,但是不管怎样,在迁移之后有一个很清晰的平均处理时间的下降。 最后,我们已经对现在的结果非常的满意,而且我们肯定不会怀念MongoDB了。它的性能非常好,它的处理方案使其它数据库相比之下黯然失色,并且查询数据的过程与MongoDB相比实在太令人满意了(尤其是对于non开发者而言)。尽管我们仍然还有一个服务(Olery Feedback)仍旧使用MongoDB(尽管这运行在一个独立的,相对小的集群上),我们仍然打算将来把它移植到PostgreSQL上。
|

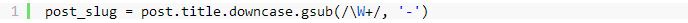







 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved