 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 6条MongoDB数据库设计的经验法则
发布日期:2016-4-26 17:4:35
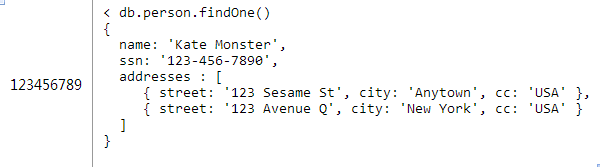
一、背景 “我有丰富的sql使用经验,甚至会各种数据库,甚至连mssql,但我是个MongoDB的初学者。我应该怎样在MongoDB中针对一对多关系进行建模?”这是问及最多的问题之一。 在这里我没法简单的给出答案,原因是这有很多方案去实现。接下来我会教导你如何针对一对多进行建模。 这个话题有很多内容需要讨论,我会用三个部分进行说明。在第一部分,我会讨论针对一对多关系建模的三种基础方案。在第二部分我将会覆盖更多高级内容,包括反范式化与双向引用。在最后的一部分,我将会回顾各种选择,并给出做决定时需要考虑的因素。 很多初学者认为在MongoDB中针对一对多建模唯一的方案就是在父文档中内嵌一个数组子文档,但这是不准确的。由于你可以在MongoDB内嵌一个文档不代表你就必须这么做。 当你设计一个MongoDB数据库结构,首先你需要问自己一个在使用关系型数据库时不会考虑的问题:这个关系中集合的大小是什么样的规模?你需要意识到一对很少,一对许多,一对非常多之间细微的区别。不同的情况下你的建模也将不同。 Basics: Modeling One-to-Few 1.一对很少 针对个人需要保存多个地址进行建模的场景下使用内嵌文档是很合适,可以在person文档中嵌入addresses数组文档,如图1所示:
图1 图1的这种设计具有内嵌文档设计中所有的优缺点。
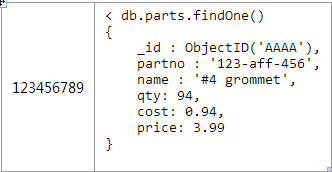
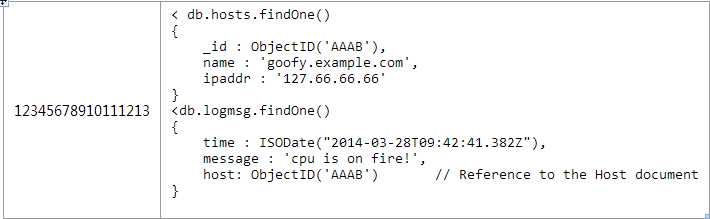
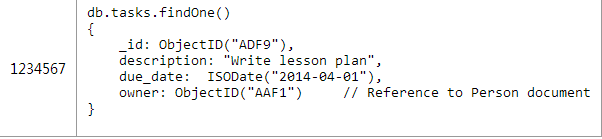
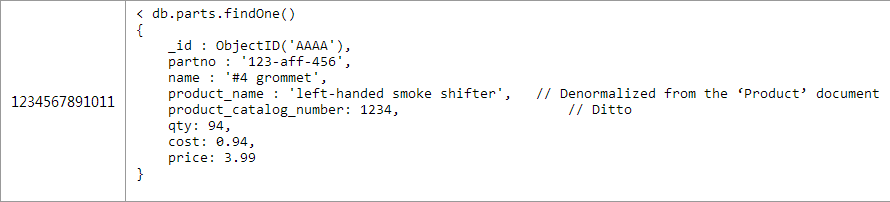
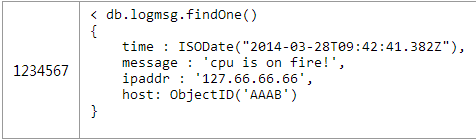
例如,如果你是在对一个任务跟踪系统进行建模,每个用户将会被分配若干个任务。内嵌这些任务到用户文档在遇到“查询昨天所有的任务”这样的问题时将会非常困难。我会在下一篇文章针对这个用例提供一些适当的设计。 Basics: One-to-Many 2.一对许多 以产品零件订货系统为例。每个商品有数百个可替换的零件,但不会超过数千个。这个用例很适合使用间接引用---将零件的objectid作为数组存放在商品文档中(在这个例子中的ObjectID我使用更加易读的2字节,现实世界中他们可能是由12个字节组成的)。 每个零件都将有他们自己的文档对象,如图2所示: 每个产品的文档对象中parts数组中将会存放多个零件的ObjectID,如图3所示 : 在获取特定产品中所有零件,需要一个应用层级别的join 为了能快速的执行查询,必须确保products.catalog_number有索引。当然由于零件中parts._id一定是有索引的,所以这也会很高效。 这种引用的方式是对内嵌优缺点的补充。每个零件是个单独的文档,能很容易的独立去搜索和更新他们。需要一条单独的语句去获取零件的具体内容是使用这种建模方式需要考虑的一个问题(请仔细思考这个问题,在第二章反反范式化中,我们还会讨论这个问题) 这种建模方式中的零件部分可以被多个产品使用,所以在多对多时不需要一张单独的连接表。 Basics: One-to-Squillions 3.一对非常多 我们用一个收集各种机器日志的例子来讨论一对非常多的问题。由于每个mongodb的文档有16M的大小限制,所以即使你是存储ObjectID也是不够的。我们可以使用很经典的处理方法“父级引用”---用一个文档存储主机,在每个日志文档中保存这个主机的ObjectID。如图4所示: 以下是个和第二中方案稍微不同的应用级别的join用来查找一台主机最近5000条的日志信息,如图5所示: 所以,即使这种简单的讨论也有能察觉出mongobd的建模和关系模型建模的不同之处。你必须要注意一下两个因素: Will the entities on the “N” side of the One-to-N ever need to stand alone? 一对多中的多是否需要一个单独的实体。 What is the cardinality of the relationship: is it one-to-few; one-to-many; or one-to-squillions? 这个关系中集合的规模是一对很少,很多,还是非常多。 Based on these factors, you can pick one of the three basic One-to-N schema designs: 基于以上因素来决定采取以下三种建模的方式
二、 在面的文章中我介绍了三种基本的设计方案:
同时说明了在选择方案时需要考虑两个关键因素。
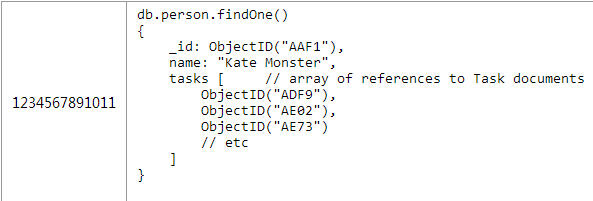
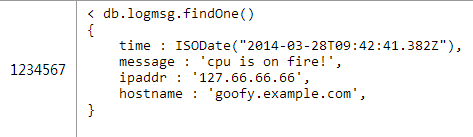
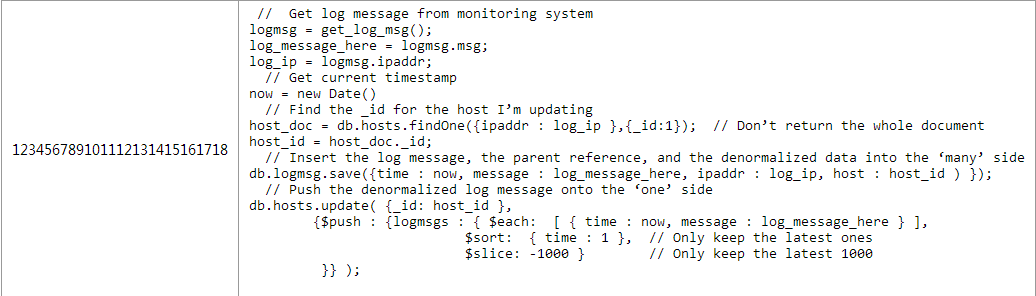
在掌握了以上基础技术后,我将会介绍更为高级的主题:双向关联与反范式化。 1.双向关联 若你想让你的设计更酷,你可以让引用的“one”端与“many”端同时保存对方的引用。 以上一篇文章讨论过的任务跟踪系统为例。有person与task两个集合,one-to-n的关系是从person端到task端。在需要获取person所有的task这个场景下需要在person这个对象中保存有task的id数组,如图6所示的代码。 在某些场景中这个应用需要显示任务的列表(例如显示一个多人协作项目中所有的任务),为了能够快速的获取某个用户负责的项目可以在task对象中嵌入附加的person引用关系。如图7所示: 这个方案具有所有的一对多方案的优缺点,但是通过添加附加的引用关系。在task文档对象中添加额外的“owner”引用可以很快的找到某个task的所有者,但是如果想将一个task分配给其他person就需要更新引用中的person和task这两个对象(熟悉关系数据库的童鞋会发现这样就没法保证操作的原子性。当然,这对任务跟踪系统来说并没有什么问题,但是你必须考虑你的用例是否能够容忍) 2.在一对多关系中应用反范式 在你的设计中加入反范式,能使你避免应用层级别的join读取,当然,代价是这也会让你在更新是需要操作更多数据。下面我会举个例子来进行说明 3.反范式Many -< One 以产品和零件为例,你可以在parts数组中冗余存储零件的名字。图8所示的是没有加入反范式设计的结构。 反范式化意味着你不需要执行一个应用层级别的join去显示一个产品所有的零件名字,当然如果你同时还需要其他零件信息那这个应用层的join是避免不了的。如图9所示 在使得获取零件名字简单的同时,执行一个应用层级别的join会和之前的代码有些区别,具体如图10所示: 反范式化在节省你读的代价的同时会带来更新的代价:如果你将零件的名字冗余到产品的文档对象中,那么你想更改某个零件的名字你就必须同时更新所有包含这个零件的产品对象。 在一个读比写频率高的多的系统里,反范式是有使用的意义的。如果你很经常的需要高效的读取冗余的数据,但是几乎不去变更他d话,那么付出更新上的代价还是值得的。更新的频率越高,这种设计方案的带来的好处越少。 例如:假设零件的名字变化的频率很低,但是零件的库存变化很频繁,那么你可以冗余零件的名字到产品对象中,但是别冗余零件的库存。 需要注意的是,一旦你冗余了一个字段,那么对于这个字段的更新将不在是原子的。和上面双向引用的例子一样,如果你在零件对象中更新了零件的名字,那么更新产品对象中保存的名字字段前将会存在短时间的不一致。 4.反范式One -< Many 你也可以冗余one端的数据到many端,如图11所示: 若你冗余产品的名字到零件表中,那么一旦更新产品的名字就必须更新所有和这个产品有关的零件,这比起只更新一个产品对象来说代价明显更大。这种情况下,更应该慎重的考虑读写频率。 5.在一对很多的关系中应用反范式 在日志系统这个一对许多的例子中也可以应用反范式化的技术。你可以将one端(主机对象)冗余到日志对象中,或反之。 图12所示的例子将主机中的IP地址冗余到日志对象中。 如果想获取最近某个ip地址的日志信息就变的很简单,只需要一条语句而不是之前的两条就能完成。如图13所示: 实际上,如果one端只有少量的信息存储,你甚至可以全部冗余存储到多端上,合并两个对象。如图14所示: 在另一方面,也可以冗余数据到one端。比如说你想在主机文档中保存最近的1000条日志,可以使用mongodb 2.4中新加入的$eache/$slice功能来保证list有序而且只保存1000条。 日志对象保存在logmsg集合中,同时冗余到hosts对象中。这样即使hosts对象中超过1000条的数据也不会导致日志对象丢失。如图15所示: 通过在查询中使用投影参数 (类似{_id:1})的方式在不需要使用logmsgs数组的情况下避免获取整个mongodb对象,1000个日志信息带来的网络开销是很大的。 在一对多的情况下,需要慎重的考虑读和更新的频率。冗余日志信息到主机文档对象中只有在日志对象几乎不会发生更新的情况下才是个好的决定。 三、总结 在这篇文章里,我介绍了对三种基础方案,内嵌文档,子引用,父引用的补充选择。如以下几点:
四、 这篇文章是系列的最后一篇。在第一篇文章里,我介绍了三种针对“一对多 ”关系建模的基础方案。在第二篇文章中,我介绍了对基础方案的扩展:双向关联与反范式化。 反范式可以让你避免一些应用层级别的join,但这也会让更新变的更复杂,开销更大。不过冗余那些读取频率远远大于更新频率的字段还是值得的。 如果你还没有读过前两篇文章,欢迎一览。 让我们回顾下这些方案 你可以采取内嵌,或者建立one端或者N端的引用,也可以三者兼而有之。 你可以在one端或者N端冗余多个字段 下面所示的是你需要谨记:
1.设计指南 当你在MongoDB中对“一对多”关系进行建模,你有很多的方案可供选择,所以你必须很谨慎的去考虑数据的结构。下面这些问题是你必须认真思考的:
2.数据建模设计指南
|









 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved