 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 Scrapy+Flask+Mongodb+Swift开发攻略二
发布日期:2016-4-19 18:4:54
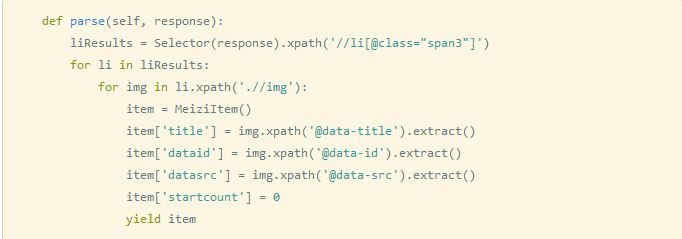
Scrapy+Flask+Mongodb+Swift开发全攻略二 一、准备工作 好的,在这篇攻略开始之前,先要干两件事。第一件事是找到spiders文件夹里的dbmeizi_scrapy.py。打开它,在上一篇攻略里,这个爬虫文件是这么写的,代码为图1所示: 图1 现在我们需要改成这样,代码如图2所示:
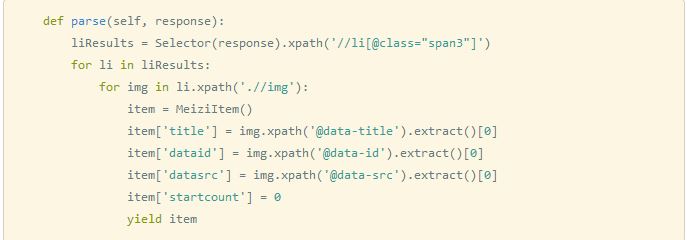
图2 原因很简单,与mssql不同,由于用extract这个方法得到的是一个数组,而我们的每一个字段实际上是一个string并非是一个array,若不取第一个值,那么存入mongodb之后,title这个key对应的value是一个数组,这会导致我们将mongodb里的数据转换成json之后需要在客户端再进行分解。这样操作起来很麻烦。 第二件要做的事,是删除我们上一个爬虫爬取的数据。 如图3:
图3 好了,再次运行我们的爬虫,scrapy crawl dbmeiziSpider,再检查一下数据库里的内容,是不是以前的每个字段对应的内容已经从数组变成了string了。如图4所示:
图4 二、开始编写服务器 现在我们要从iOS程序员变成一个菜鸟级别的server端选手。不过能用自己编写的iOS客户端从自己写的server下载数据,也是挺好的 在编写服务器端的时候确保你用pip安装了下面的两个库。 1.pymongo 2.Flask 我们的服务端代码如图5所示:
图5 图5所示的代码就是我们的服务端代码,虽然只有短短28行,python的强大之处也在于此。 接下来让我来一行一行的解释一下。 前面5行就是import各种我们需要的库,若后面你使用python server.py运行的时候提示错误,很可能是你的机子上缺少上述的库。 app = Flask(__name__)这句话就是利用Flask的构造方法生成一个Flask实例,name是什么?简单来说,你创建的任何python文件(.py),都会有一个内置属性,叫做__name__,他有两个用途,如果你在命令行状态下直接运行`python .py`的时候,这个时候这个python文件里的__name__就是__main__,如果你是在别的python文件里import *.py,那么这个name的东西就是这个Python文件的文件名。so,这个东西常常用来判断,你是在import还是直接在命令行里运行这个文件。 因此在上一行,我们生成了一个Flask实例并且把这个实例赋给了app这个变量。 mongoClient = pymongo.MongoClient('localhost', 27017) db = mongoClient['dbmeizi'] 这两句很简单,就是用pymongo这个第三方库,打开我们的mongodb数据库,并且拿到我们的dbmeizi这个database。 def toJson(data): return json.dumps(data, default=json_util.default) 这句话,我们定义了一个函数,用来把mongodb里的数据转换为json格式。用来返回给我们的ios客户端。 @app.route('/meizi/', methods=['GET']) 这句话的意思就是Flask的一种写法,意思就是当我们发起了一个request,并且这个request的方法是get,url是"localhost:5000/meizi/"这种的的时候,我们就执行findmeizi()这个方法。如图6所示:
图6 这个方法就是我们的http server监测到用户发起get请求,并且URL是形如'http://127.0.0.1:5000/sightings/?offset=0&limit=3'的时候,我们取出limit这个值,赋给lim这个变量,然后取出offset这个值,赋给off。 然后呢?利用我们的db(就是刚才利用pymongo获取的mongodb实例),取出‘meizi’这个collection,skip(off)的意思就是跳过前面多少行,limit(lim)表示从数据库取出多少个值。 整句话的意思就是,从meizi这个collection里跳过前off个值,取后面的lim个值。 现在取到的数据都在results变量里,跟mssql一样,了解mssql的都知道。我们遍历results,放入json_results这个数组里,然后把数组转换成json格式返回给客户端。 我们运行一下试试。如图7所示
图7 图7所示的结果数据已经返回给浏览器了。 这时候我们编写一个简单的iOS客户端,验证一下。 我们建立一个swift的iOS程序,用cocoapods安装下列库。如图8的代码所示:
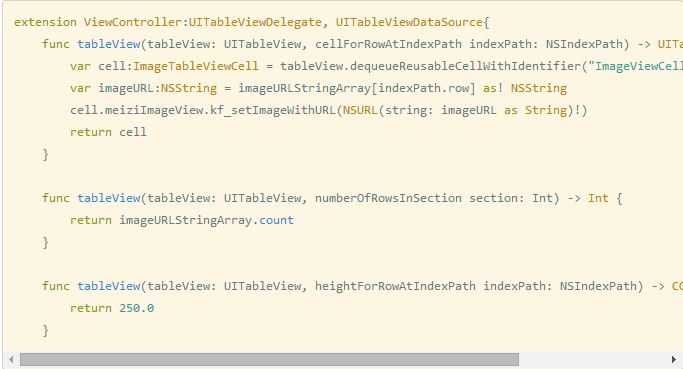
图8 请注意,cocoapods务必升级到最新版,要不然安装swift的第三方库会出现问题。 我写了一个超简单的iOS客户单,纯验证下服务端是否有效。如下面的代码所示: 图9 图10 运行一下上面所示的代码。
图11 如图11的显示结果,数据返回正确。 但是,这样还远远没有结束,爬虫完全是个半成品,服务端简直就是个玩笑,客户端什么炫酷特效交互都没有,做这样的东西简直是打自己的脸。
现在,到了我展现真正实力的时候了。
|












 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved