 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 用Redis来实现高并发分布式序列号生成服务
发布日期:2016-4-19 17:4:47
用Redis来实现高并发分布式序列号生成服务 一、序列号的构成 为了建立良好的数据治理方案,作数据掌握、分析、统计、商业智能等用途,业务数据的编码制定通常都会遵循一定的规则,一般来讲,都会有自己的编码规则与自增序列构成。例如我们常见的身份证号、银行卡号、社保电脑号等等。 我们以某公司产品标识码(代表该产品的唯一编码)的构成为例,入下所示:
简单说来,业务编码是由规则与序列构成,规则是允许定义与编辑的,序列通常要求并发安全。整个序列号生成规则要求读写并发安全。 二、序列号生成方案 Redis的优势:
由于以上等优势,我们采用Redis存储并持久化序列与业务规则来配置和管理整个序列号的产生。 规则定义举例:前缀+时间(YYYYMMDD)+所使用的序列(指定长度),那么产生的序列号类似于SO20150520000124
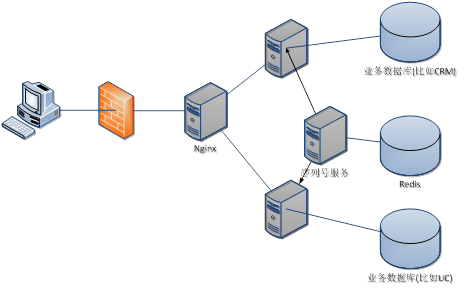
尽管规则的配置更适合使用表结构来存储,但为了构建分布式的数据库集群,通常都会采用分库和分表(分片)的方式,在这种要求下,我们将规则的配置和序列都放在Redis,以便于提供独立的全局序列生成服务.而不用担心数据库伸缩带来的影响.如图1所示的序列号生成服务部署图:
三、序列号实现方案 1. 规则配置管理 在Redis的设计中,要想实现比如以下代码: select * from users where user.location="shanghai" 以上这种方式的查询,是没办法通过value进行比较得出结果的。但能通过不同的数据结构类型组合来做到这一点。例如以下所示的数据定义 users:1 {name:Jack,age:28,location:shanghai} users:2 {name:Frank,age:30,location:beijing} users:location:shanghai [1] 其中
这样通过两次简单的Redis命令调用就可以实现我们上面的查询。 Jedis jedis = jedisPool.getResource(); Set //... //通过hgetall获取对应的user信息 jedis.hgetAll("users:" + shanghaiIDs[0]); 通过以上说明的设计,可以实现简单的条件查询。但这样的问题也很多,首先需要多维护一个ID索引的集合,其次对于一些复杂查询无能为力(当然也不能期望Redis实现像关系数据库那样的查询,Redis不是干这的)。针对本序列号生成方案,这种方式完全是够用的,可以直接参考本节的代码示例。 如果想更进一步,Redis2.6集成了Lua(Redis是用ANSI C写的,可以想象支持Lua是一件很自然的事),可以通过eval命令,直接在RedisServer环境中执行Lua脚本,也就是说可以让你用Lua脚本,对Redis中存储的key value进行操作,这个意义就大了,甚至可以将系统所需的各种业务写成一个个lua脚本,提前加载进入Redis,然后对于请求的响应,只需要调用一个个lua脚本就行。(当然这些操作也完全可以使用Jedis来完成,但显然lua效率更高) 例如,现在我们要实现一个‘所有年龄(age)大于28岁的用户(user)’这样一个查询,那么通过以下所示的Lua脚本就可以实现。代码如以下内容: public static final String SCRIPT = "local resultKeys={};" + "for k,v in ipairs(KEYS) do " + " local tmp = redis.call('hget', v, 'age');" + " if tmp > ARGV[1] then " + " table.insert(resultKeys,v);" + " end;" + " end;" + "return resultKeys;"; 执行脚本代码,如以下内容: Jedis jedis = jedisPool.getResource(); jedis.auth(auth); List List args.add("28"); List return resultKeys; 请注意,以上所示的代码中使用的是evalsha命令,该命令参数的不是直接用Lua脚本字符串,它并不像mssql,而是提前已经加载到Redis中的函数的一个SHA索引,通过以下的代码将系统中所有需要执行的函数提前加载到Redis中,通常在自己的系统中维护一个函数哈希表funcTable,后续需要实现什么功能,就从函数表中获取对应功能的SHA索引,通过evalsha调用就行。如以下代码: String shaFuncKey = jedis.scriptLoad(SCRIPT);//加载脚本到Redis中,获取sha索引 funcTable.put(funcName_age, shaFuncKey);//添加到系统维护的函数表中 通过以上的方法,便可以使较为复杂的查询放到Redis中去执行,提高效率。 由上面可见,想要将全部业务代码都使用lua脚本来实现的业务系统是可能的,lua脚本等同于关系型数据库中的存储过程或者函数。当然,全部使用lua的开发成本未必不大,毕竟不是关系型数据库,存储思维不同。
//配置生成规则(CRUD): //假设销售单号生成规则:prefix+time+seq //生成之后的结果类似于:SO20150520023014 //------模拟常规数据库操作------ //添加数据 shardedJedis.hset("rules", "somaster", "name:销售单号,prefix:SO,time:YYYYMMDD,seq:seq_so,seq_len:6"); shardedJedis.hset("rules", "pomaster", "name:采购单号,prefix:PO,time:YYYYMMDD,seq:seq_po,seq_len:6"); shardedJedis.hset("rules", "test", "name:test,prefix:PO,time:YYYYMMDD,seq:seq_po,seq_len:6"); //判断某个值是否存在 System.out.println(shardedJedis.hexists("rules", "test")); // 删除指定的值 System.out.println(shardedJedis.hdel("rules", "test")); // 获取指定的值 System.out.println(shardedJedis.hget("rules", "somaster")); // 获取所有的keys System.out.println(shardedJedis.hkeys("rules")); // 获取所有的values System.out.println(shardedJedis.hvals("rules")); //更新 = 插入同名的key System.out.println("update before:"+shardedJedis.hvals("rules")); System.out.println(shardedJedis.hset("rules", "somaster", "new test somaster")); System.out.println("update after:"+shardedJedis.hvals("rules")); 我示例代码中使用的是hash而不是直接使用key-value来存储,是更优的方案。至此CRUD都能直接满足了,最后,你获取到所有values,需要自己处理分页。 也可以使用list和set组合的方式存储。这种方式是将list index和set key对应起来,根据序号进行分页是容易的,但在每次新增和删除时,都需要修改序号和key的对应关系。 两者相比,使用hash的成本显然更低,也不易出错。 2. 序列号的使用 Redis中对序列的生成早已考虑周到,使用单线程操作序列的方式足以保证并发安全,而且,它的使用也比mssql简单。更多操作详见官网API
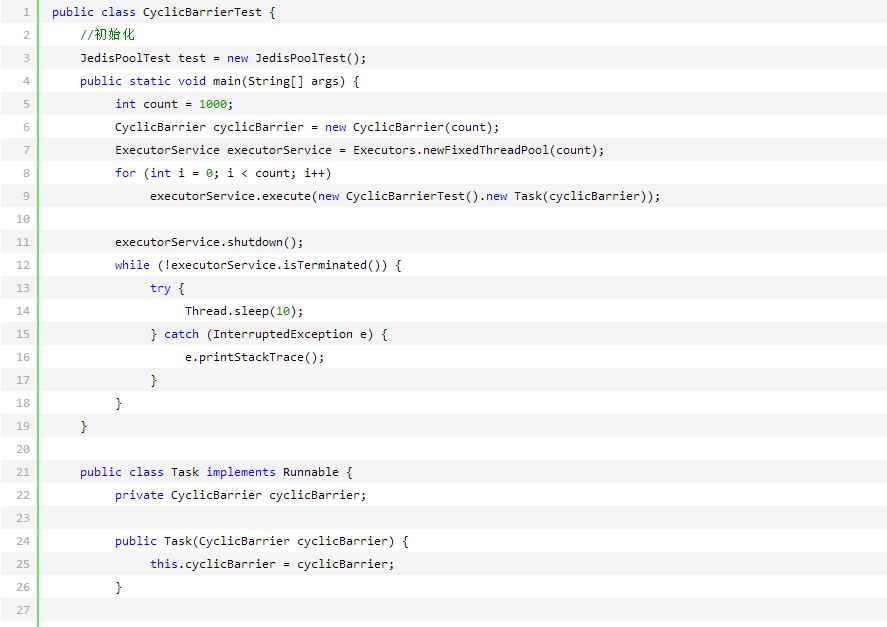
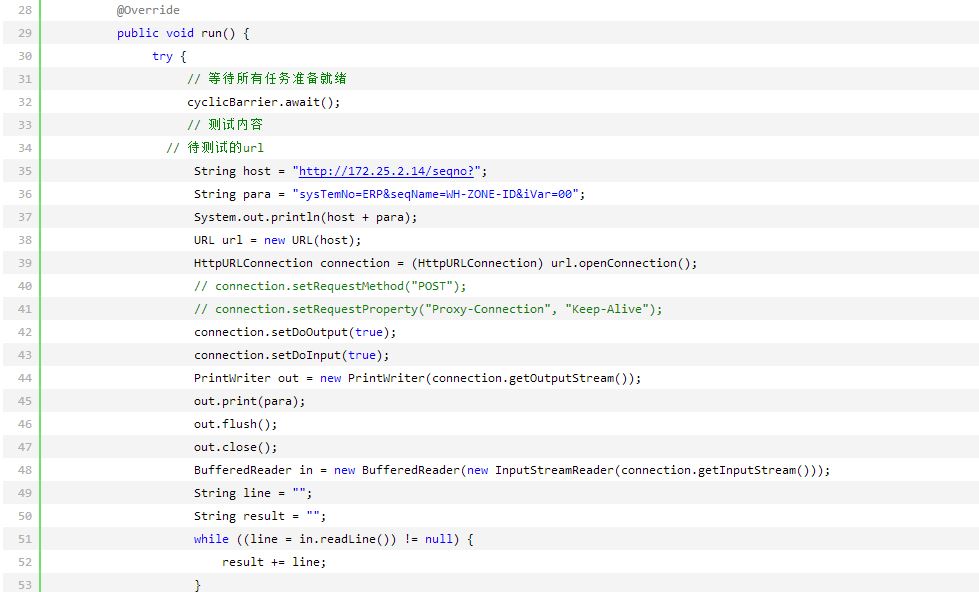
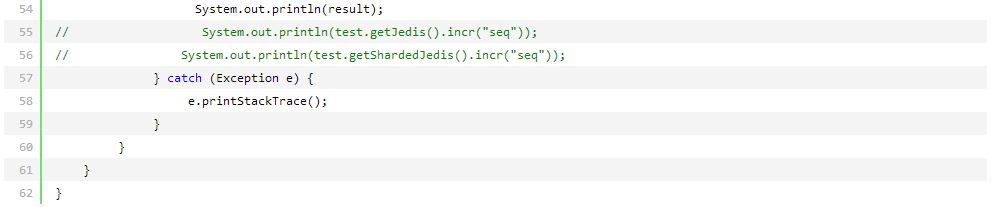
//sequence System.out.println("seq:"+shardedJedis.incr("seq")); System.out.println("seq:"+shardedJedis.incr("seq")); System.out.println("another_seq:"+shardedJedis.incr("another_seq")); 最后,生成序列服务只需要通过对应的规则名,获取规则表达式,解析之后结合序列号,最终生成即可。 四、并发测试 这里我们使用CyclicBarrier做并发测试,CyclicBarrier会开启指定数量的线程,等待这些线程就绪之后,同时执行测试内容,以达到真实并发的测试目的。 Loadrunner等压力测试工具也能完成测试任务。代码如图2所示:
图2 运行上面的代码的测试结果: 单台Redis未经任何设置,500并发100% pass,到1000并发时只有67%pass率,这时候存在连接超时与被拒的情形。但时不存在任何重复号码或丢失号码。500并发数其实已经完全满足我当前系统的要求。比起mssql,Redis本身可以集群扩展,完全能够应对将来更高的并发需求
|



 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved