 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 浅谈MongoDB性能优化
发布日期:2016-4-18 23:4:15
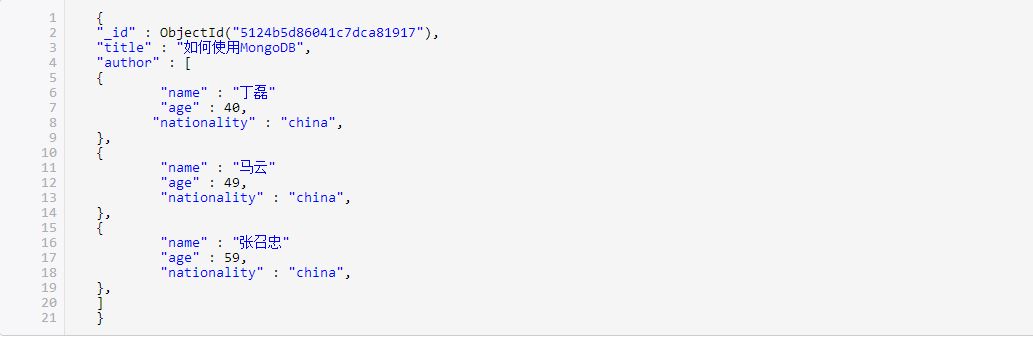
浅谈MongoDB性能优化 性能与用户量 “如何能够让软件拥有更高的性能?”,这是一个大部分开发者都思考过的问题。因为性能往往决定了一个软件的质量,若你开发的是一个互联网产品,你的产品性能将更加受到考验,由于你面对的是广大的互联网用户,他们可不是那么有耐心的。甚至可以说,页面的加载速度每增加一秒,结果就是使你失去一部分用户,所以,加载速度与用户量是成反比的。那么用户能够接受的加载速度到底是多少呢? 根据统计,如果页面加载时间超过10s那么用户就会离开,如果1s–10s的话就需要有提示,但是如果我们的页面没有提示的话,我们需要多快的加载速度呢?答案为:1s 。 这是站在一个产品经理的角度来说的,但是如果站在一个技术人员的角度来说呢?加载速度与用户量就是成正比的,你的用户数量越多,那么需要处理的数据当然也就越多,加载速度当然也就越慢。这其实是一件很有趣的事,因此所以如果你的产品如果是一件激动人心的产品,技术人员的工作就是让软件的性能与用户的数量同时增长,甚至性能增长要快于用户量的增长。 数据库性能对软件整体性能的影响是不言而喻的,那么,当我们使用MongoDB时改如何提高数据库性能呢? 一.范式化和反范式化? 在项目设计阶段,对性能调优非常重要的一步是明确集合的用途。 从性能优化的角度来看,在集合的设计上,我们需要考虑的是集合中数据的常用操作,比如我们需要设计一个日志(log)集合,日志的查看频率不高,但是写入频率却很高,那么我们就可以得到这个集合中常用的操作是更新(增删改)。若我们要保存的是城市列表呢?显而易见,这个集合是一个查看频率很高,但写入频率很低的集合,那么常用的操作就是查询。 对于频繁更新与频繁查询的集合,我们最需要关注的重点是他们的范式化程度,在上篇范式化与反范式化文章的介绍中我们了解到,范式化和反范式化的合理运用对于性能的提高至关重要。然而这种设计的使用非常灵活,假设现在我们需要存储一篇图书及其作者,在MongoDB中的关联就可以体现为以下几种形式: 1. 完全分离(范式化设计) 示例1,代码如下所示:
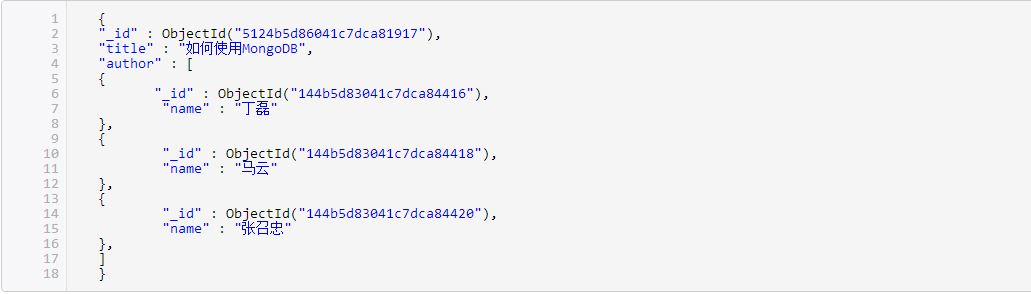
图1 在上面的这个示例中,我们将作者(comment) 的id数组作为一个字段添加到了图书中去。这样的设计方式是在非关系型数据库中常用的,也就是我们所说的范式化设计。不同于mssql,在MongoDB中我们将与主键没有直接关系的图书单独提取到另一个集合,用存储主键的方式进行关联查询。当我们要查询文章和评论时需要先查询到所需的文章,再从文章中获取评论id,最后用获得的完整的文章及其评论。在这种情况下查询性能显然是不理想的。但当某位作者的信息需要修改时,范式化的维护优势就凸显出来了,我们无需考虑此作者关联的图书,直接进行修改此作者的字段即可。 2. 完全内嵌(反范式化设计) 示例2,代码如下所示: 图2 在图2的示例中我们将作者的字段完全嵌入到了图书中去,在查询的时候直接查询图书即可获得所对应作者的全部信息,但是由于一个作者可能有多本著作,当修改某位作者的信息时时,我们需要遍历所有图书以找到该作者,将其修改。 3. 部分内嵌(折中方案) 示例3,代码如下所示: 图3 在上面的这个示例中,这次我们将作者字段中的最常用的一部分提取出来。当我们只需要获得图书和作者名时,无需再次进入作者集合进行查询,仅在图书集合查询即可获得。 这种方式其实是一种相对折中的方式,既保证了查询效率,也保证的更新效率。但这样的方式显然要比前两种较难以掌握,难点在于需要与实际业务进行结合来寻找合适的提取字段。如同示例3所述,名字显然不是一个经常修改的字段,这样的字段如果提取出来是没问题的,但如果提取出来的字段是一个经常修改的字段(比如age)的话,我们依旧在更新这个字段时需要大范围的寻找并依此进行更新。 在以上的三个示例中:
所以在实际的工作中我们需要根据自己实际的需要来设计表中的字段,以获得最高的效率。 二、.理解填充因子 什么是填充因子? 填充因子(padding factor)是MongoDB为文档的扩展而预留的增长空间,因为MongoDB的文档是以顺序表的方式存储的,每个文档之间会非常紧凑。 元素之间没有多余的可增长空间。 当我们对顺序表中某个元素的大小进行增长的时候,就会导致原来分配的空间不足,只能要求其向后移动。 当修改元素移动后,后续插入的文档都会提供一定的填充因子,以便于文档频繁的修改,如果没有不再有文档因增大而移动的话,后续插入的文档的填充因子会依此减小。 之所以重要填充因子的理解,是由于文档的移动非常消耗性能,频繁的移动会大大增加系统的负担,在实际开发中最有可能会让文档体积变大的因素是数组,所以如果我们的文档会频繁修改并增大空间的话,则一定要充分考虑填充因子。 那么如果我们的文档是个常常会扩展的话,应该如何提高性能? 两种方案
图4 是的,这样看起来可能不太优雅…但有时却很有效!当我们对这个文档进行增长式修改时,只要将stuff字段删掉即可。当然,这个stuff字段随便你怎么起名,包括里边的填充字符当然也是可以随意添加的。 三、准确利用索引 索引对于一个数据库的影响相信大家一定了解,如果一个查询命令进入到数据库中后,查询优化器没有找到合适的索引,那么数据库会进行全集合扫描(在RDBMS中也叫全表扫描),全集合查询对于性能的影响是灾难性的。没有索引的查询就如同在词典那毫无规律的海量词汇中获得某个你想要的词汇,但这个词典是没有目录的,只能通过逐页来查找。这样的查找可能会让你耗费几个小时的时间,但如果要求你查询词汇的频率如同用户访问的频率一样的话。。。嘿嘿,我相信你一定会大喊“老子不干了!”。显然计算机不会这样喊,它一直是一个勤勤恳恳的员工,不论多么苛刻的请求他都会完成。所以请通过索引善待你的计算机:D。 在MongoDB中索引的类型与RDBMS中大体一致,与mssql不一致,我们不做过多重复,我们来看一下在MongoDB中如何才能更高效的利用索引。 1.索引越少越好 索引可以极大地提高查询性能,那么索引是不是越多越好?答案是否定的,并且索引并非越多越好,而是越少越好。每当你建立一个索引时,系统会为你添加一个索引表,用于索引指定的列,然而当你对已建立索引的列进行插入或修改时,数据库则需要对原来的索引表进行重新排序,重新排序的过程非常消耗性能,但应对少量的索引压力并不是很大,但如果索引的数量较多的话对于性能的影响可想而知。所以在创建索引时需要谨慎建立索引,要把每个索引的功能都要发挥到极致,也就是说在可以满足索引需求的情况下,索引的数量越少越好。 隐式索引 代码如下所示 图5 我们在查询时可以迅速的将age,no字段进行排序,隐式索引指的是如果我们想要排序的字段包含在已建立的复合索引中则无需重复建立索引。 图6 如以上两个排序查询,均可使用上面的复合索引,而不需要重新建立索引。 翻转索引 代码如下所示: 图7 翻转索引很好理解,就是我们在排序查询时无需考虑索引列的方向,例如这个例子中我们在查询时可以将排序条件写为”{‘age’: 0}”,依旧不会影响性能。 2.索引列颗粒越小越好 什么叫颗粒越小越好?在索引列中每个数据的重复数量称为颗粒,也叫作索引的基数。如果数据的颗粒过大,索引就无法发挥该有的性能。例如,我们拥有一个”age”列索引,如果在”age”列中,20岁占了50%,如果现在要查询一个20岁,名叫”Tom”的人,我们则需要在表的50%的数据中查询,索引的作用大大降低。所以,我们在建立索引时要尽量将数据颗粒小的列放在索引左侧,以保证索引发挥最大的作用。 原文: http://www.cnblogs.com/mokafamily/p/4102829.html 上一条: 数据库设计规范化 下一条: Redis时延问题分析与应对方法
|



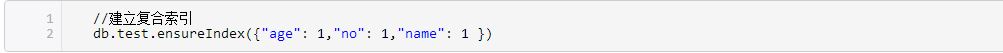




 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved