 重庆域名服务热线 :023-61066666 66887777 89082222 重庆域名服务热线 :023-61066666 66887777 89082222 |   |
| 重庆域名服务热线 :023-61066666 66887777 89082222 | |
 在阿里云上搭建大规模实时数据流处理系统
发布日期:2016-1-20 11:1:28
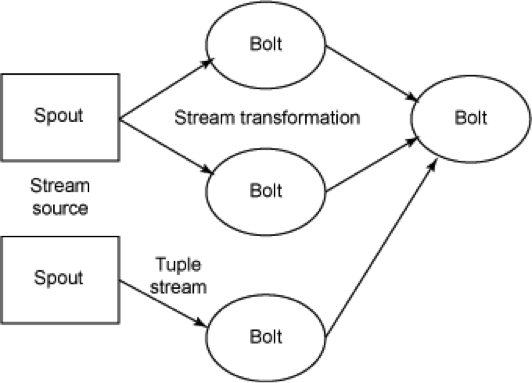
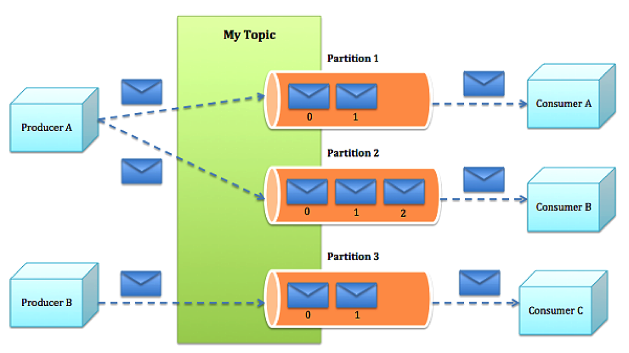
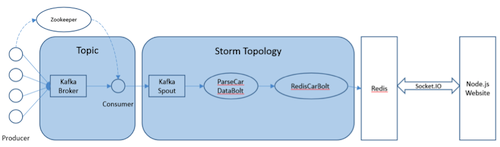
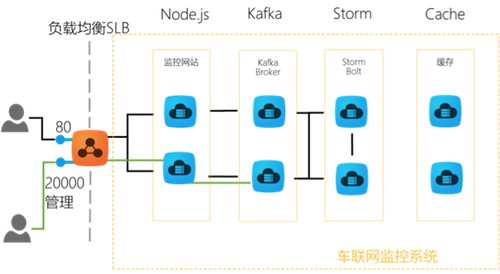
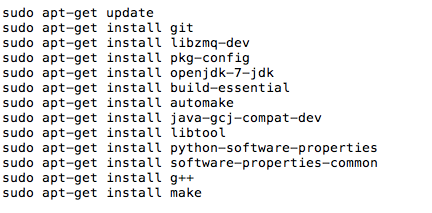
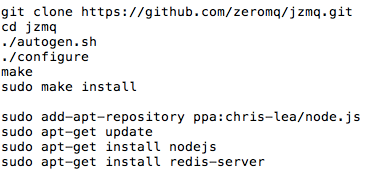
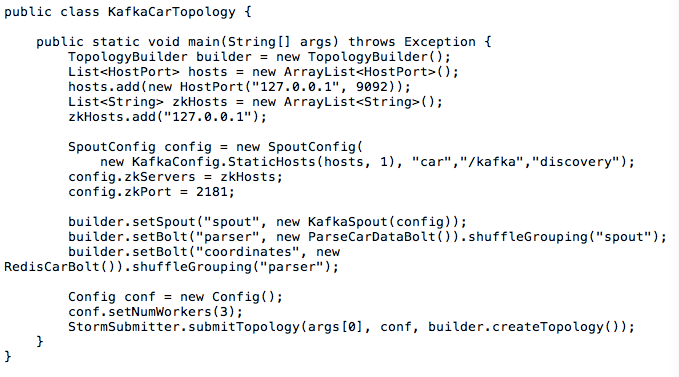
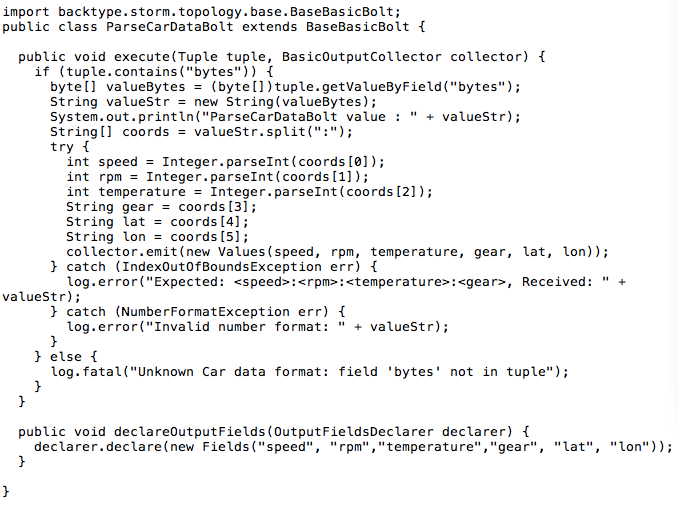
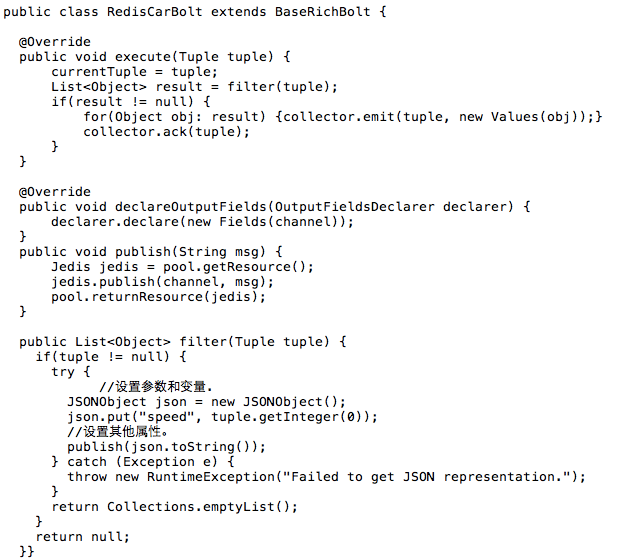
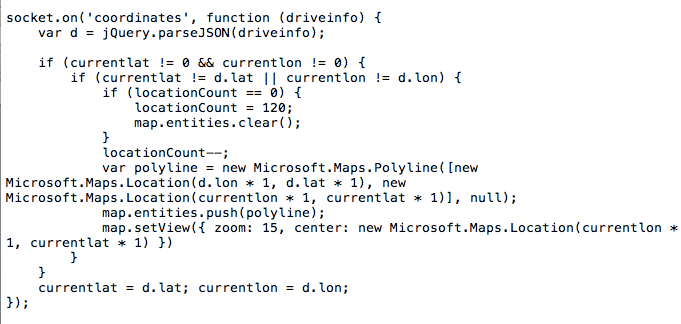
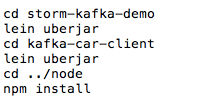
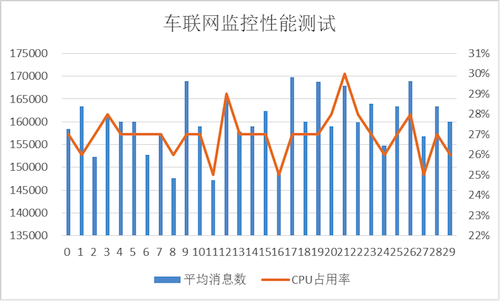
在阿里云上搭建大规模实时数据流处理系统 在大数据时代,数据规模变得越来越大。由于数据的增长速度和非结构化的特性,常用的软硬件工具已无法在用户可容忍的时间内对数据进行采集、管理和处理。本文主要介绍如何在阿里云上使用Kafka和Storm搭建大规模消息分发和实时数据流处理系统,以及这个过程中主要遭遇的一些挑战。实践主要立足建立一套汽车状态实时监控系统,可以在阿里云上立即进行部署。 实时大数据处理利器——Storm和Kafka 在大数据时代,随着可获取数据渠道的增多,比如常见的电子商务、网络、传感器的数据流、太空数据等,数据规模也变得越来越大;与此同时,不同的渠道往往产生更多的数据类型,这些衍生的数据增长非常之快,规模非常之大。大数据时代各个机构可谓是坐拥金山,然而目前大数据技术的应用却仍然存在众多挑战,主要出现在数据收集、存储、处理和可视化几个过程。具体过程如下所示: 1. 数据收集 Gartner的Merv Adrian对大数据有这样一个定义:“大数据让常用硬件软件工具无法在用户可容忍时间内对数据进行采集、管理和处理。” [1] 麦肯锡全球研究院在2011年5月也有这样一个概念:“大数据是指超出典型数据库软件工具采集、存储、管理和分析能力的数据集。” [2] 从上面的定义可以看出,大数据最大的挑战在于如何在有限时间内对数据进行处理和分析,并得到有用信息。 2. 数据处理 大数据处理中最著名的工具是Hadoop,不过它并不是一套实时系统。为了解决这个问题,计算机工程师们又开发了Storm和Kafka。Apache Storm是一套开源的分布式实时计算系统。最早由Nathan Marz [3] 开发,在被Twitter收购后开源,并在2014年9月起成为Apache顶级开源项目。Storm被广泛用于各种商业网站,包括Twitter、Yelp、Groupon、百度、淘宝等。Storm的使用场景非常广泛,例如实时分析、在线机器学习、连续计算、分部署RPC、ET|等。Storm有着非常快的处理速度,单节点可以达到百万个元组每秒,此外它还具有高扩展、容错、保证数据处理等特性。 图1是Storm的一个简单的架构。如下图所示: Apache Kafka也是一个开源的系统,旨在提供一个统一的,高吞吐、低延迟的分布式消息处理平台来对实时数据进行处理。它最早由LinkedIn开发,开源于2011年并被贡献给了Apache。Kafka区别于传统RabbitMQ、Apache ActiveMQ等消息系统的地方主要在于:分布式系统特性,易于扩展;为发布和订阅提供高吞吐量;支持多订阅,可以自动平衡消费者;可以将消息持久化到磁盘,可以用于批量消费,例如ETL等。 Kafka架构如下图所示: 在阿里云上部署Storm和Kafka 我们需要设计一个实时车辆监控系统,这个系统要将汽车驾驶过程中实时的位置,速度,转速,油耗以及转速发送到系统中,从而可以实时计算出车流量和污染物排放量。这个系统的目标是要能同事支持10万辆车同时发送消息,在最高峰能满足100万辆车。为了实现如此规模的消息分发和吞吐,我们基于Kafka和Storm来设计实现。同时为了满足高扩展性,我们将Storm和Kafka分别部署到不同的服务器上,如果需要更多的计算能力,可以随时通过创建新的服务器的方式来完成。此外为了满足高可用性,每台相同功能的服务器也需要至少部署2台,这样一旦一台服务器出现问题,另外一台服务器也可以持续提供服务。 在实体服务器上部署Storm和Kafka等系统涉及到大量服务器集群和软件的安装部署,这个过程需要花费大量时间,而云计算则很好的弥补了这一点——提供各种虚拟服务器和镜像功能,加快基础设施和软件的部署过程。 基于云的车联网监控系统架构 我们需要2台服务器来构建Kafka代理服务器,在Storm中还需要2台服务器来运行Spout和2个Bolt,另外在Redis层则需要2台服务器来部署缓存,再加上2台服务器作为Web服务器。服务器架构图如图4所示。 在部署车联网监控系统之前,用户首先需要在每台服务器上部署相应的软件,包括Git、Libzmq、Java、G++等,用于代码编译和相关软件安装。用户可以使用SSH连接到相应的机器。用户名密码则会由阿里云以邮件或者短消息的方式提供给用户。 在车联网实时监控系统中,我们需要部署4种不同类型的服务器,这几种服务器分别是网站前台服务器、Kafka服务器、Storm服务器和缓存服务器,以满足上面提到的高扩展性的要求。在每一种类型的服务器部署完成之后,用户都可以通过阿里云镜像的功能,创建一个能随时使用的镜像,这样在扩展服务器的时候就用户就不需要重新安装软件,直接通过镜像就可以了创建服务器。 以下命令需要在所有服务器上运行以安装相应的软件,如下图所示: 以下命令安装在缓存服务器和Kafka服务器上,如下图所示: 另外,我们还需要在Storm的服务器安装maven和lein用于代码编译,如下图所示: 在Kafka服务器上安装Kafka,如下图所示: 对于Storm和Kafka的安装,到这一步已基本完成,接下去需要分别创建镜像。创建镜像的方法是先创建阿里云快照,然后通过将快照转换为镜像的方式完成。具体步骤如下所示: 首先在阿里云的管理界面选择云服务器,随后选择该服务器的磁盘列表,点击创建快照。 然后输入快照名称并确认。 阿里云会自动为云服务器的系统盘创建快照,当创建完成以后,会出现“创建自定义镜像”按钮。 然后点击“创建自定义镜像”的按钮,阿里云就会将这个快照转换为镜像,可以在阿里云ECS管理界面的自定义镜像栏中看到。如下图所示: 接下来,我们通过镜像可以直接创建相同配置的ECS服务器。 (图6 从自定义镜像中创建云服务器) 当然,在自动扩展实现上,云服务并不需要用户去手动执行,这里我们使用阿里云的ECS REST API自动通过镜像创建机器。可以参考以下Python代码,自动创建阿里云ECS虚拟机: 基于Storm和Kafka的车辆信息实时监控系统打造 接下来需要做的就是将车辆信息实时监控系统部署到系统中。这个系统演示了如何编写一个Storm的Topology,从Kafka消息系统中将信息读取出来。我们使用Kafka的客户端模拟从世界各地发送车辆实时信息给Kafka集群,然后Storm Topology会把这些消息通过Bolts将坐标转换为Json对象,并且使用GeoJSON在Bing Map上显示车辆的实时位置、温度、转速以及速度等等信息。Topology还会将信息写到Redis缓存中,然后Node.js通过socket.io读取Redis中的信息,并且使用d3js显示在页面上。 首先,我们需要编写Kafka 生产者的部分代码,这个代码主要是用来模拟读取汽车的实时数据并向Kafka集群进行发送,我们实现了一个KafkaCarDataProducer类,通过配置ProducerConfig来创建一个Producer对象来发送数据。它可以用来连接到Zookeeper,或者直接是Kafka 代理。例如:kafkaclient.cloudapp.net:2181或者0:kafkaclient.cloudapp.net:9092。代码中我们根据不同的连接字符串设置不同配置。伪代码如下: 然后我们就可以直接通过下面代码来发送消息: 接下来我们还需要编写3个Storm类,首先是创建Storm的Topology,这个类叫KafkaCarTopology,我们创建了一个叫car的topic,然后定义本机一个hosts和Zookeeper hosts,最后再创建一个Spout,叫做KafkaSpout,然后添加ParseCarDataBolt连接到KafkaSout,再创建一个RedisCarBolt,用于将结果写入Redis缓存。最后根据参数创建3个Worker,提交Storm Topology。 在这个拓扑结构中,我们有2个Bolt用于数据的处理,第一个叫ParserCarDataBolt,这个Bolt主要将Kafka传出的消息转换为Json格式,它继承BaseBasicBolt,在execute函数中通过collector提交数据,同时重载了declareOutputFields函数,通知下一个Bolt的数据格式。代码如下所示: 数据会被写入RedisCarBolt,再写入到Redis缓存中。它继承自BaseRichBolt,需要重载prepare和excute方法来处理消息元组。此外还需要重载prepare和cleanup函数,几个关键的函数如下所示: 最后我们还需要编写一些Node.js的代码,用来保证在页面上通过socket.io进行通讯,实时将最终数据从Redis里面读取出来,并在BingMap上显示。 到此为止,一个简单的车辆信息实时监控系统就可以实现了,我们通过bash脚本进行编译,并把他安装到相应的服务器上,比如下列代码需要被安装在Storm的服务器上: 有一点需要注意的是,由于在编译过程中需要自动下载Storm库,在阿里云的国内机房的虚拟机很有可能需要设置代理进行。设置代理的方法也很简单,通过对lein命令增加以下参数就可以了:http_proxy=http://URL:PORT 接着我们在网页上访问http://webhostname或者运行node.js的服务器,就会看到下面的网页,同时发现网页将同步刷新汽车的实时位置、速度、转速等。如下图所示: 对车联网监控系统的性能测试 接下来我们对这个系统进行了一个简单的吞吐量测试。我们只有1个Topic,使用5个partition、3个worker、1个Spout和2个Bolt,在一台2核2GB的ECS上运行。我们使用了另外4台客户端,每个客户端有4核8G内存,分别启动40个线程不断向这个系统实时发送汽车信息,模拟160台汽车发送的情况,其消息发送数量和CPU占用率情况如下图所示。 从上图中可以看出,平均每辆汽车客户端会模拟每秒给系统发送了1000条消息,总的吞吐量达到16万条左右,此时平均的CPU占用率大约在30%左右。如果系统是完全线性的,在系统CPU占用率达到90%的情况下,大约能处理48万条消息。不过实际情况中,在阿里云ECS上,却发现CPU达到50%以后,就不再上升,而客户端发送消息的延时也逐步增加。 经过分析以后可以发现,由于ECS的磁盘性能无法和物理机的SSD磁盘相比,所以在Kafka消息大量写入磁盘的过程中,吞吐量下降,磁盘读写负担变得非常大。这时我们增加了Kafka的Broker和Storm的Spout的数量,将消息分布式地分发到多台ECS上,从而实现了消息吞吐量的线性增加。 在这个系统中,我们不推荐使用大核和大内存的机器,而推荐使用多台2核2GB的服务器分布式地处理消息。这也是云计算处理大数据的原则所在,使用横向扩展而不用纵向扩展。 结论 至此我们介绍了利用Storm和Kafka实现大数据的实时处理,而且还介绍了如何在云上通过镜像快速地创建这套系统。此外,我们还介绍了如何对Storm、Kafka、Redis以及Node.js开发出一个实时的车辆信息监控系统。这个系统能够实现高性能、大吞吐量和高并发。当然,随着大数据的快速发展,我们相信还会有越来越多好的工具和产品出现在市场上,到那时我们从大数据中获取有效的信息就会变得更加容易和便捷。有了云计算的帮助,开发的周期也会变得越来越短。
|










 业务QQ:
业务QQ:  联系电话: 023-61066666 66887777 89082222
联系电话: 023-61066666 66887777 89082222 离线联系: 13452888882 13452888883 13452888886
离线联系: 13452888882 13452888883 13452888886  备案专线: 023-60887777 备案专员QQ:
备案专线: 023-60887777 备案专员QQ: 联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved
联系地址: 重庆市九龙坡区石桥铺一城精英国际40层17号 Copyright © 重庆典名科技有限公司 023dns.com All Rights Reserved